
论文地址
论文概述
- 提出了一种白盒对抗来对付char-level的分类器。
- 使用原子级别的翻转,仅需要根据one-hot的梯度将两个token进行交换。
- 在执行对抗训练的时候可以变得更加鲁棒。
- 使用语义约束使得该方案也能作用于word-level的分类器。
论文简介
- 对抗样本是被设计用来使机器学习模型获得不佳的性能。
对抗样本暴露了模型表现不佳的输入空间区域,这有助于理解和改进模型,如果用这些数据作为训练样本,那么可以增强模型的鲁棒性。 - 以前都是使用的黑盒对抗,没有任何模型参数的明确知识。
- 在白盒攻击中,使用模型的完整知识来开发最坏情况的攻击,这可以揭示更大的漏洞。
- 核心方法是原子翻转操作,根据模型相对于onehot输入的方向导数,将两个token进行交换
方案详解
- 翻转可以用如下来表示,i表示第i个词,j表示第j个字符:

- 可以从沿该向量的方向导数获得损失变化的一阶近似值
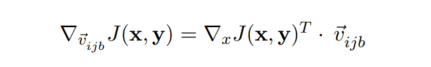
- 选择梯度减少最大的方向

- 多次翻转可以使用greedy search或者beam search
实验
保证新出现的word不在词表中,主要是防止修改原句的语义

鲁棒性

word-level
单词级别的对抗性操作更有可能改变文本的含义,这使得使用语义保留约束成为必要。
For example, changing the word good to bad changes the sentiment of the sentence “this was a good movie”. In fact, we expect the model to predict a different label after such a change.
从outflip中找到一组详细的公式描述

单词翻转的条件
- 余弦相似度大于0.8
- 两个词的pos要一致
- 不允许替换停用词,因为对于许多停用词,很难找到替换它们仍然会使句子在语法上正确的情况。也不允许为了相同的目的将一个单词更改为具有相同词素的另一个单词。
使用embedding层的输出作为词的表示

备注
- 原文虽然给出了word-level的方案,但是没有做实验。
- 原文用的模型是one-hot做输入的模型,而现在常用的embedding层使用lookup的方式跳过了one-hot这个步骤,在复现的时候还是要将embedding层换为one-hot+dense的形式,现在大多数文本模型训练前加载pretrain的参数,所以实现的时候要把embedding的参数加载到dense层上,实际测试发现这两个矩阵在torch中是转置的关系。
