1. 赛题数据理理解
1.1 数据整体介绍
本赛题中训练集为15000个参保对象的共计1368146条历史结算明细数据, 其中包括参保⼈人ID、流⽔水号、50个脱敏敏数值特(FTR0-FTR50)、FTR51⽂本特征和发⽣时间特征,共计52维有效数据以及是否为欺诈参保⼈人的LABEL,如图1所示。测试集则为2500个参保对象的23万多历史数据,然后对这些参保对象进行是否欺诈分类预测,模型预测能力以AUC为指标来进⾏评定。下图1为数据概况: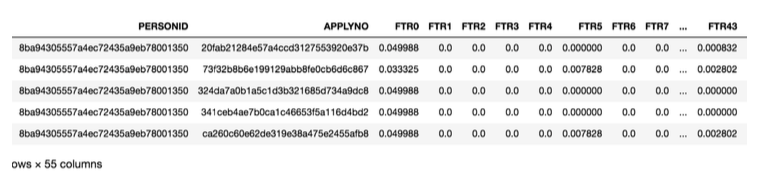
1.2 数据初步分析
(a)时间:数据时间跨度为2015年3月至2016年2月,可以发现从上半年各个月份就诊次数趋于平稳,从九月份开始就诊次数骤然增加,并且保持了较高就诊次数直到来年的二月份才有轻微的下降。
(b)脱敏字段:FTR0-FTR50为脱敏的标准化后数据,且很稀疏——包含大量的0,初步构想删除大量为0的特征。
(c)无用特征:字段PPLYNO为交易涉别号,为脱敏数据,在实际中没有任何参考价值,故删除
(d)重点特征FTR51:FTR51特征由于含有固定的ABCED,可能为某特定含义组合,如药物SKU或就诊内容和机构分类等可以进行文本分类、字符串拆分统计等分析处理。
2.特征⼯工程
2.1 思路简介
(a)由于样本量很少,最终模型应当保持足够简单性以及可解释性,这样便于模型稳定以及工业在线化欺诈识别。
(b)由于数据集为参保对象的历史数据,可对数值类特征进行聚合操作提取特征;根据业务理解,根据费用高、保险报销频繁、医疗费高等可着重提取最大值、总和、非零值等特征。
(c)根据欺诈行为之操作频繁特征,我们可以提取某个时间段内的数值型特征相关聚合数据,如滑窗操作——7天、15天、30天、60天和一年等时间窗下的最大值、总和、非零值特征,这些局部特征对欺诈行为分析肯定有巨大作用。除此之外还可以提取相应时间窗又的 报销频次特征和时间间隔特征。
(d)与时间窗又滑动统计不同,基于时间历史信息,我们可以在进行局部特征挖掘时遵循选择性时间降采样——从不同时间颗粒度大小的角度来分析历史结算明细数据并进行聚合统计分析。
(e)FTR51不考虑业务含义,按照文本处理,基于Doc2Vector或Word2Vector来训练出一组向量来作为各参保对象的特征。
(f)FTR51不考虑业务含义,若其为机构与就诊部门分类等信息,则拆分为A、B、C、E、D 及其组合模块来聚合统计(全范围统计、时间滑窗统计和分段时间统计等)最常参保的模块和不同种类数,因为一般欺诈参保对象的医疗机构多于普通参保对象。
(g)FTR51若其为药物处方,可以统计每月的买药次数和种类、总的买药次数和种类、当月与上个月买药次数差的绝对值、当月与上月相比的新增药物种类、当月与上月相比的减少药物种类、每月买药次数均值与方差统计。
(h)通过观察FTR51,将其每个逗号隔开的字符串视为一个单词,然后基于时间颗粒度来统 计每个单词出现的次数、平均值、标准差等统计特征形成自定义的词频统计值,然后基于词频统计值进行LDA(LatentDirichletAllocation)进行文本主题分类生成一个描述向量作为 特征。
2.2 特征工程
1.FTR0-FTR50特征⼯程
该部分数据为脱敏敏数据,故我们⽆无法了了解实际背后的业务含义,因此我们只能从特征的⻆度进行处理。下⾯面详细阐述该部分数据的特征⼯程建立:
(a)我们对FTR0-FTR50经常数据可视化,分析出其包含⼤量的0,FTR0到FTR50的0值⽐例如图2-1 ,对于⼀些0值⽐例⾼达99%的列我们可以考虑删除。此外在进⾏求平均值等统计值,计算时,也要考虑着0值⽐例过多的影响。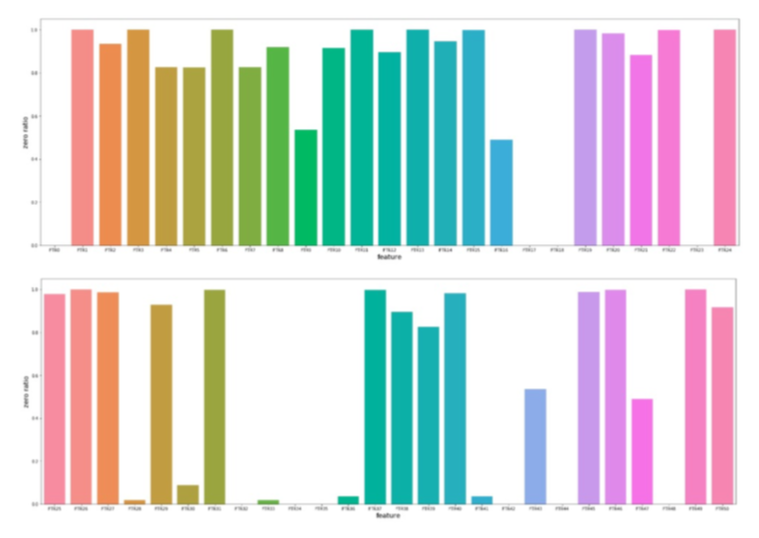
(b)团队将FTR0-FTR50删除的部分特征后,剔除⽅方差较⼩小(实际特征没有区分度),以及经过corr热力图之后,删除相关性大于90%的特征。下图为相关性热力图: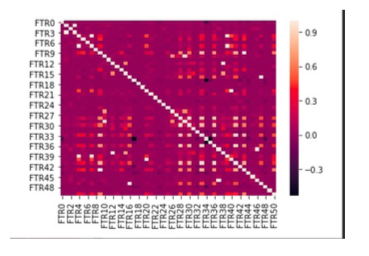
(c)团队将处理得到的特征,再进行unique()查询,设定值小于10以下的为类别特征。团队没有采⽤传统的onehot处理,⽽是在此基础上进⾏交叉处理理。如:两列数据,⼀个是性别⼀个是年龄,团队进⾏交叉构建,构建为中年男,⽼年⼥这样的特征,⽤于寻找交叉信息背后的关联。根据先验知识,⼀般青年男会比老年男有较少的就诊次数。
(d)将FTR0-FTR50删除的部分特征,进⾏聚合统计获取总体时间颗粒度上的最大值、总和等统计特征。
2.FTR51特征⼯程
(a)我们对原始数据进行处理,并对就诊区间进行分段。通过研究发现用户购买次数20-50次人数最多。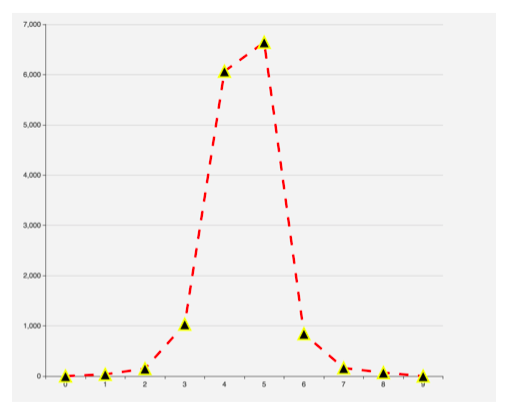
(b)FTR51若其为药物处方,可以统计每月的买药次数和种类、总的买药次数和种类、当月与上个月买药次数差的绝对值、当月与上月相比的新增药物种类、当月与上月相比的减少药物种类、每月买药次数均值与方差统计。
(c)假如将用户购买的记录作为一个文本,那么我们就可以使用部分nlp的思想进行对用户建模。TF_IDF,word2vec、LDA。计算了所有药品的tf-idf,得到了四万多维的特征,考虑到这样的特征过于稀疏,我们对这些特征与用户标签进行lasso回归,删除了大量的权重为零的特征。以FTR51_B种类数为例,可以看出其分布密度,正常⼈员主要集中在种类数很低的水平,而欺诈用户则集中在非常高的水平。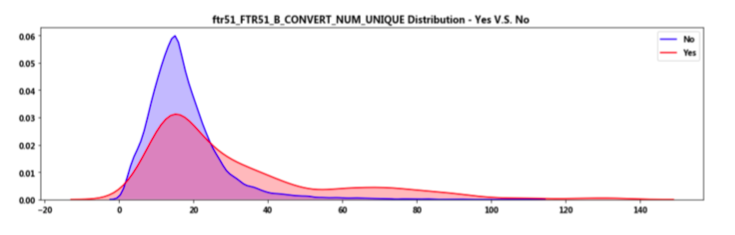
(d)对数据进行重采样:由于FTR51一些记录中有很多以逗号隔开的记录,我们对其进行这样的采样处理——先以逗号分裂后形成列表,以该列表长度为根据,复制相同的记录数据,仅仅不同的是FTR51全部变成单一的形如“A1B1C1E1D0” 的数据,然后删除原先的记录数据。再基于这样生成的新数据进行和未采样数据相同的特征挖掘过程。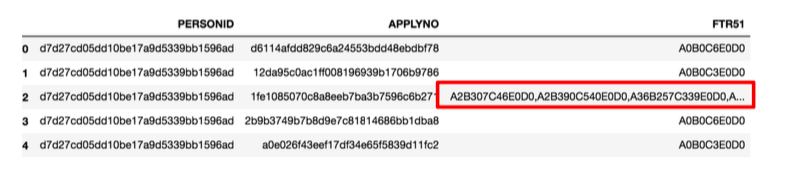
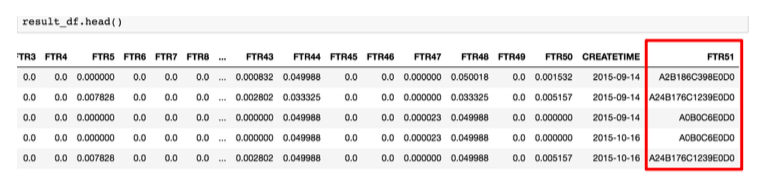
e)通过观察FTR51,将其每个逗号隔开的字符串视为一个单词,然后基于一定的时间颗粒度来聚合每个单词出现的次数,但是这样的矩阵型数据是无法直接作为模型的输入的,所以接着我们沿着时间轴求和、平均值、标准差等统计特征形成自定义的多种词频统计值,原理如图(图中只显示了5个单词,实际单词数量达4W多个)。最后基于图中右边的多种词频统计值分别进行LDA(LatentDirichletAllocation)进行文本主题分类生成多个描述向量作为特征。下图为3天为时间粒度⾃定义的词频统计值。
(f)若其为药物处方,统计每月的买药次数和种类、总的买药次数和种类、当月与上个月买药次数差的绝对值、当月与上月相比的新增药物种类、当月与上月相比的减少药物种类、每月买药次数均值与方差统计。
3.就诊次数(时间)特征⼯工程
时间是衡量一个是否存在欺诈行为的⼀个重要指标。药品消耗期为10天的话,正常情况的购买时间粒度为8天左右,假如⼀个⽤户连续购买时间间隔短以及一次购买量大,该⽤户可能存在欺诈行为。团队将每天的购买情况做⼀个统计,除去几个异常点之外,购买趋势大致稳定。如下图所示: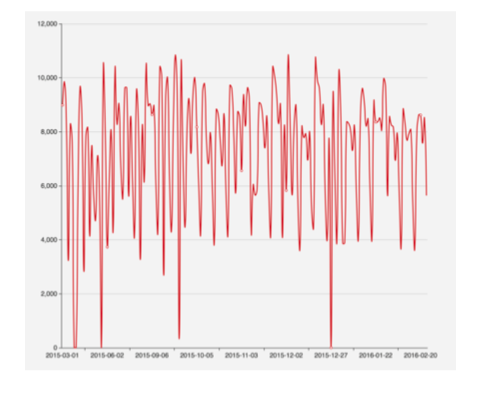
团队在做实际数据搜集的时候,发现标签为1的⽤户骗保⾏为均在⼯作日中,这也可以根据实际情况来得到。平时工作日的时候每天消费药品数量巨大,越容易逃开专业人员的审核。在实际建模的过程中也会发现用户⼀天购买量很大,连续交易频繁。基于此,团队根据实际业务场景进行建模。下⾯⼀一介绍:
(a)统计总体时间范围内的参保⼈人员参保记录总次数、统计总体时间范围内的参保⼈人员参保记录时间去重后的总次数。对两特征进⾏相除操作获取以天为单位的平均次数。
(b)按时间分段(2015年年与2016年年)统计参保就诊总次数,然后取其最⼤大值作为特征。
(c)按⾃自然⽉月时间分段统计参保就诊总次数,然后取其最⼤大值作为特征。 (d)按⾃自然天时间分段统计参保就诊总次数,然后取其最⼤大值作为特征。
(e)按时间窗⼝口进⾏行行滑窗——3D、7D、15D、30D、60D,统计参保就诊总次数,然后取其 最⼤大值作为特征。这可以过滤到在某⼀一⼩小时间段内参保频率很⾼高的参保⼈人员,从业务背景 上分析,这类⼈人员很有可能就是欺诈⼈人员。
(f)对于就诊次数统计不不同时间颗粒度下的就诊连续度变化指标:例如,以3天的时间颗粒分段来对就诊次数进行采样,如图所示,其中0代表该人员在此统计时间段内没有结算记录;然后就可以形成⼀个连续的非0二维数组,然后计算每个子数组的⻓度,并以此为基础来计算波动标准差,将其作为就诊连续度变化指标。当参保人员非0子数组个数不大于1,此时⽤负数对该指标特征填充,可区分此类参保人员与其他类参保⼈人员。该指标计算原理理如图:
通过查看分布发现,该指标特征在欺诈⼈员和⾮欺诈人员的分布明显不同。如图所示,横轴1代表欺诈⼈员、0代表⾮欺诈人员,纵轴为就诊连续度变化指标值。可以看到,欺诈⼈员的就诊连续度范围更多,也表现了欺诈⼈员行为多样化的特点;⽽非欺诈人员这一指标主要集中在0-1之间,相对集中,即⾏为一般化。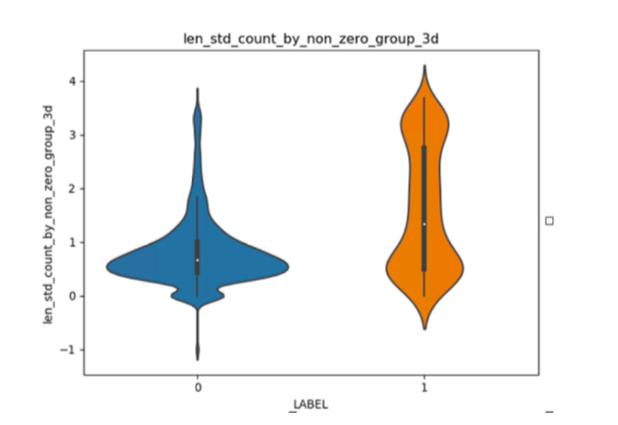
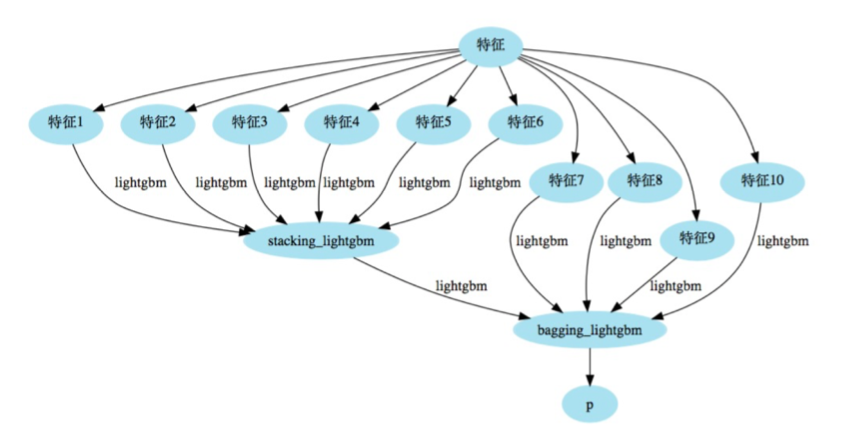
3.模型
3.1 模型细节
团队成员采用不同特征的相同模型构造模型。利用不同特征之间的差异性,将输出结果进行bagging。