
1 赛题理解和数据探索
1.1赛题理解
此题利用已有的用户属性(如个人基本信息、用户画像信等)、业务属性、消费习惯及偏好等特征,对用户进行套餐推荐,从而更好的为用户服务。
1.2 数据探索
通过对数据的探索,我们发现虽然训练集给出了12类,但是999999这个类很特殊,只有2条重复数据,因此我们决定删除该类,将问题转化为11分类。同时数据中存在少量”\N”等不合理数据,需要处理。对于1_total_fee、2_total_fee、3_total_fee、4_total_fee,我们发现很多消费集中在56、76、106、136、166等,但是数据中仍存在相当大一部分比例的小数消费,如76.3,76.1等,我们推断每月出账金额是该用户套餐消费的关键。
2 特征工程
2.1 缺失值特征填充
最终我们使用了初赛数据+复赛数据来预测测试集,原始初赛数据中,其中 age、gender、2_total_fee、3_total_fee存在缺失值”\N”,分别利用中值、众数、均值、均值填充。
2.2 业务特征
1.对于age和gender字段,除了填充缺失值以外,原数据中age和gender存在字符串形式、‘\N‘形式、整数形式,这三种也能代表客户数据的收集方式所产生的不同,将三种方式做LabelEncoder编码,对于age字段,不同年龄段套餐类型存在较大差别,故映射age为[0,10,16,24,30,40,50,60,∞] 区间。
2.此题1_total_fee至4_total_fee为用户月出账收入,每一个用户存在很大的序列关系,故用1_total_fee减/除2_total_fee,2_total_fee减/除3_total_fee,3_total_fee减/除4_total_fee,代表用户消费的时序变化。通话时长service1_caller_time减service2_caller_time,平均缴费金额pay_num除pay_times等等
2.3 统计特征
对1_total_fee至4_total_fee做统计特征,包括最大、最小、均值,对流量属性做最大、最小处理等等。
2.4 二值特征
如比较online_time 和contract_time、local_caller_time和service1_caller_time、local_caller_time和service2_caller_time等等。
2.5 试图找出不包括通话超套餐时长的特征
我们根据通话每分钟0.15元,得到如下式所示(例如):data[‘1_total_fee_out_caller1’]=data[‘1_total_fee’]- data[‘service1_caller_time’]*0.15 data[‘1_total_fee_out_caller1_ratio’]= data[‘1_total_fee_out_caller1’] / data[‘1_total_fee’]
上式表明先去除通话导致的套餐费用,然后占比总出账收入作为特征。类似做2_total_fee和service2_caller_time的处理。
2.6 计数特征和组合计数特征
做了某些特征的计数特征:包括pay_num, former_complaint_num, complaint_level, online_time, age, 1_total_fee, 2_total_fee, 3_total_fee, 4_total_fee等。类似上面的处理,但特征组合有时候更能反映用户的特性,如age和1_total_fee的组合,然后考虑计数特征,因为不同年龄段的消费存在较大差距,更好的区分出不同类别。
2.7 词袋特征
题目中单个值可能是强特,如图所示:
由图可以看出,一个值几乎可以完美区分出89950167这个套餐,由此联想到1_total_fee至4_total_fee上,将4个月出账收入拼接起来,类似统计词向量,为防止过拟合训练集,将词频低于20的不考虑在内,并最终用稀疏矩阵存储。(理解:因为每个用户有相应的套餐费用,大部分人都是月基础费用,将其one-hot处理更能反映出用户的特征,线上提升约4k。)
2.8 整数特征
观察数据发现,消费存在类似50.3,50.0,仅存在3毛钱的差别,提取出整数部分,以此来与大多数的整数消费用户达成一致,并在此基础上分别做关于整数部分的计数特征和组合计数特征。(此处线上提升约2k)
2.9 舍弃的特征
舍弃了关于1_total_fee至4_total_fee的word2vec结果,因为考虑到出账具有很强的序列关系,于是使用word2vec训练出账词向量,线下有提升,线上效果不佳。2.9.2 舍弃了关于99999830的转化率特征,做关于99999830套餐的转化率,导致结果有偏 。
3 初赛数据的使用
我们对初赛数据和复赛数据进行了K-S检验,发现初赛数据与复赛数据的p值较低,所以初赛数据与复赛数据不完全属于同一分布。这也就导致了使用先拼接数据再去提取特征的数据训练出的模型不是很理想。我们尝试使用一个分类器去区分初赛和复赛数据,同样效果不是很理想,说明初赛数据中依旧包含了有用的信息。于是我们团队以复赛数据为基础,复赛所作特征如计数特征,初赛数据直接拼接该特征,这样就保证了初复赛数据的分布相对的一致性。(线上提升约2k)
4 特征选择、模型选择和融合
在特征选择方面,去除互相关系数大于0.95的特征(保留其中一个)、去除缺失值大于90的特征、去除方差为0的特征。
我们团队最终选择LightGBM树模型,因为运算速度快、精度高,在参数选择方面,由于该题对应准确性最优,参照LightGBM文档[1],调大max_bin以及num_leaves。
在模型融合方面,模型融合能够加强模型泛化能力,我们分别单用复赛训练集预测复赛测试集得到概率值、初赛+复赛训练集预测复赛测试集得到概率值,然后将概率值以一定的比例加权,加权系数由线下交叉验证分数确定,得到融合以后的结果。
5 后处理
如下图所示: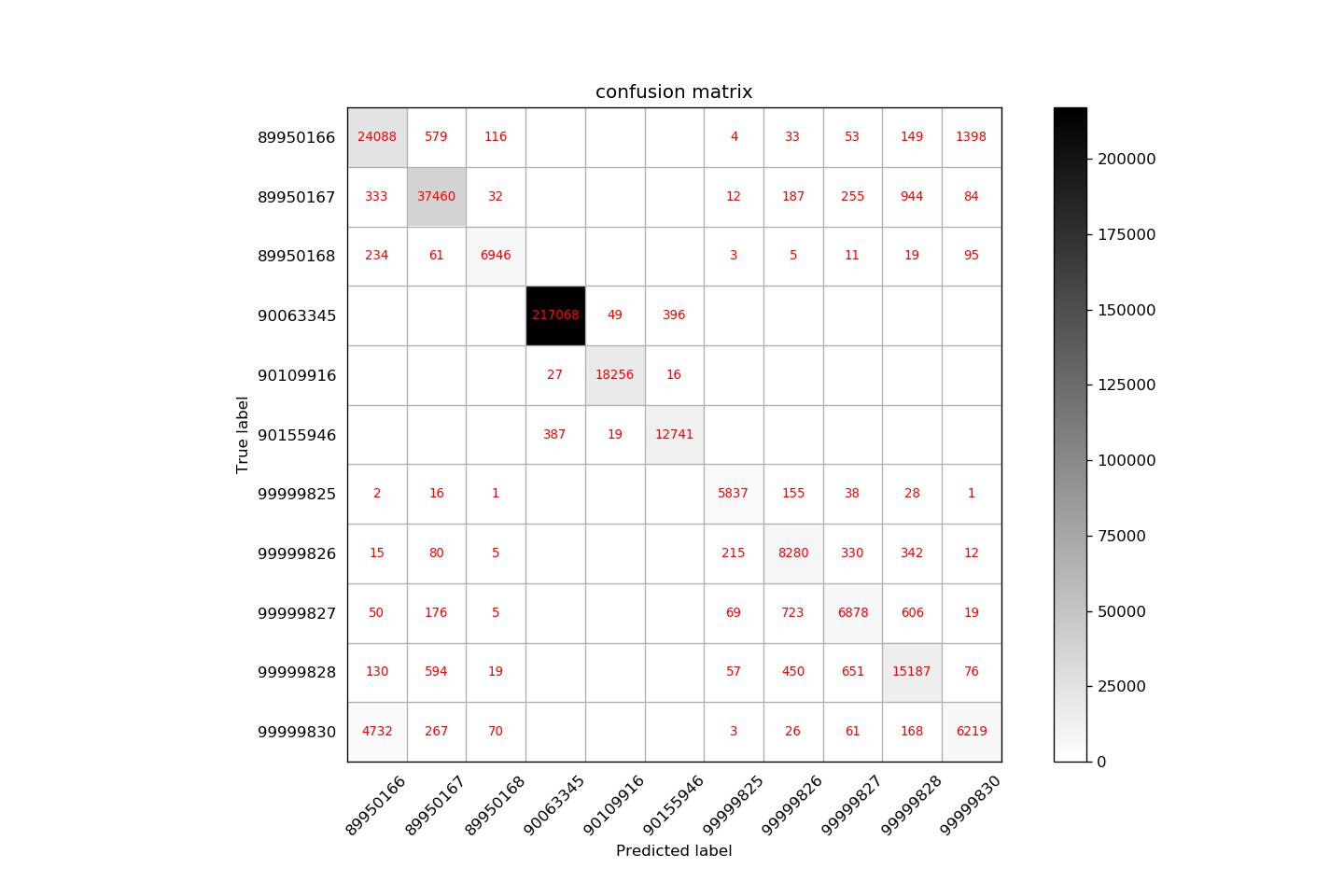
从图可看出,99999830和89950166套餐分错的类别最多,线下f1分数不到0.3,于是我们团队想到单独训练一个二分类模型,在此基础上覆盖前面的融合结果,对应二分类,可以使用前面多分类丢弃的特征即转化率特征,最终得到二分类结果并替代原多分类结果,得到最终的模型结果。(二分类想法线上提升约3k。),下图为二分类转户率的对比:
